说句实在话,最近AI圈就没平静过,所有目光基本都被DeepSeek勾走了。
没有任何前兆,不发预热文案、不搞悬念宣传,就这么悄咪咪地把R1模型的论文从22页扩充到86页,直接甩出一份开源圈能照着一步步操作的实战手册。
这波操作一出来,不管是搞技术研发的,还是做行业观察的,全被惊到了。
要知道在AI行业里,各大厂商对核心技术的保护,比护着自家保险柜里的钱还上心,DeepSeek偏要反其道而行,敢这么干,绝对是有实打实的硬底气。


论文爆更,开源亮尽家底
你发现没,现在很多AI厂商都爱走“神秘路线”。要么就扔给你一个模型权重,至于背后怎么训练、核心逻辑是什么,半个字都不多说;
要么写的论文全是生僻术语,绕来绕去把人搞懵,普通人看半天也摸不着头脑,说白了就是不想让别人照着做出一样的东西。
但DeepSeek这次完全不按常理出牌,恨不得把自家底裤都亮出来,一点都不藏着掖着。新增的这64页内容,没有一句废话,全是能直接落地的干货。

连训练数据的具体数量都公开得明明白白,靠2.6万道数学题、1.7万条代码撑起来核心训练,就连数据怎么筛选、怎么标注、不同类型数据怎么搭配组合的完整流程,都讲得清清楚楚。
这就好比别人给你一份做好的菜,顶多告诉你食材,而DeepSeek是把详细菜谱、火候大小、甚至放多少盐、什么时候翻炒都跟你说透,生怕你学不会。
不光是训练数据,连基础设施的配置图、整个训练过程的成本明细,也一股脑全摊了出来。
R1-Zero这个版本,用了64组每组8张的H800 GPU,前前后后跑了198个小时,算下来总花费是29.4万美元。这些数据在行业里,那都是堪比商业机密的存在,一般厂商打死都不会对外说,DeepSeek却大大方方公开了。

更难得的是,它还主动坦白自己踩过的坑,把过程奖励模型(PRM)为啥走不通、问题出在哪都讲得明明白白,连失败的经验都毫无保留地分享出来。
这种坦诚劲儿,在AI行业里真没几个厂商能做到。有网友调侃,这哪是什么学术论文啊,分明就是给开源圈准备的实战教科书,刚入行的新手照着这份文档学,起码能少走好几年的弯路。
换个角度想,这波论文爆更也是实力的体现,要是没点真本事,谁敢把核心技术这么兜底曝光?
要知道R1的论文去年9月就登上了Nature封面,是首个经过顶级期刊认证的主流大模型,现在又把所有细节补全,说白了就是明着跟行业喊话:这些技术我们早就玩得炉火纯青了,接下来要搞的事,只会更大。
其实开源和闭源,一直是AI圈两条完全不同的路。闭源厂商靠着技术垄断,赚得盆满钵满,把核心能力攥在自己手里,想用钱把门槛拉高;
而开源则是靠分享技术攒生态、聚人气,让更多人能接触到核心能力。
DeepSeek这波操作,就是要打破闭源厂商的垄断壁垒,让那些没那么多资金的中小企业和开发者,不用花大价钱,也能拿到能用、好用的核心技术。这才是开源的真正意义——技术不该分高低贵贱,谁都有使用和创新的权利。

实力硬刚,多模态藏后手
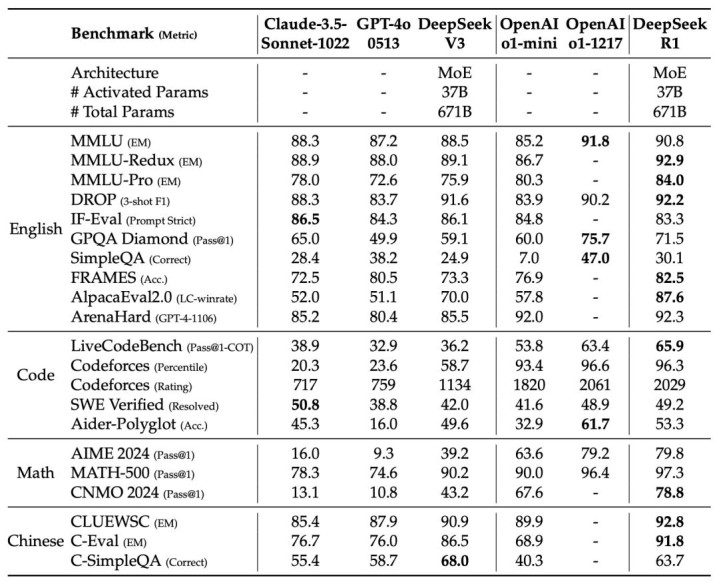
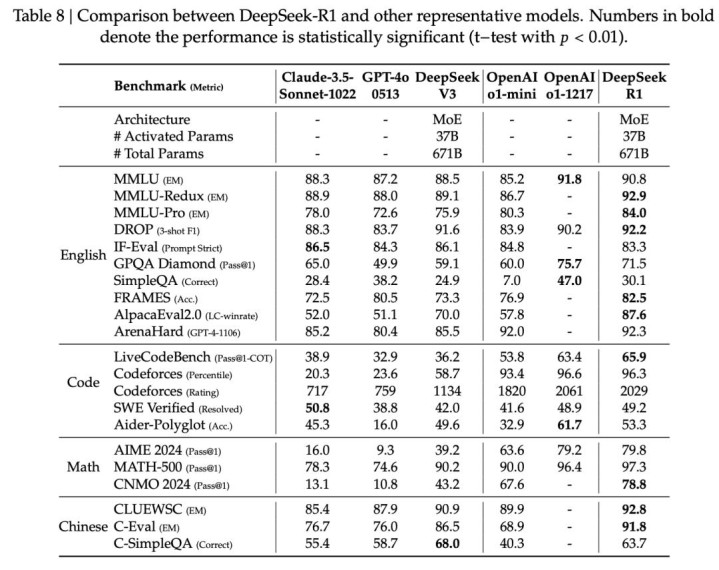
我跟你讲,这篇论文最让人佩服的,不光是细节公开得彻底,更在于R1那实打实的性能。
实测下来能明显看出,DeepSeek R1多项能力都能和OpenAI o1掰掰手腕,部分场景里甚至比o1-mini、GPT-4o和Claude 3.5还强。

要知道这可是个开源模型,还遵循MIT协议,能跟闭源顶流模型较量不落下风,这本身就是个了不起的突破。
人工评估也没掉链子,在ChatbotArena擂台赛里,R1的ELO分数相当亮眼,尤其是“风格控制”这一块,直接和OpenAI o1、Gemini-Exp-1206并列第一。
这一点特别关键,能彻底避免模型靠说漂亮话、编华丽表述讨好评审,保证回答的实在性,不搞那些花里胡哨的表面功夫。

而且有实测对比发现,R1的思考过程比不少闭源模型更完整,就算算对答案,还会考虑到其他思路,思维发散度更高,就是耗时会稍长一点,48秒左右才能给出完整思考链。
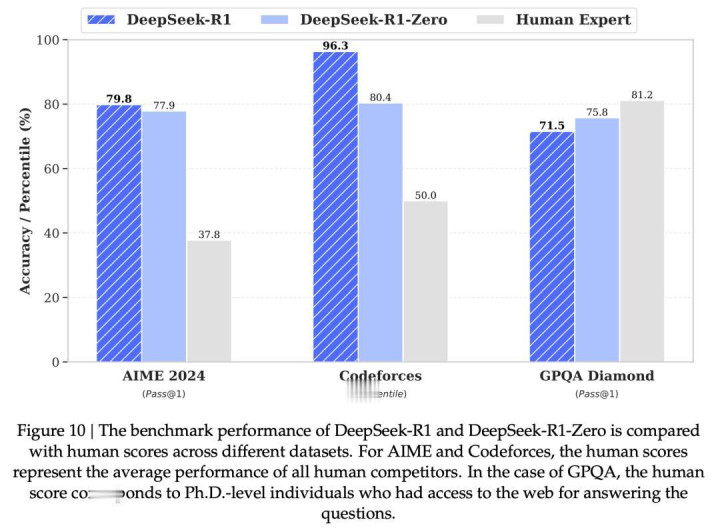
最让人惊喜的,还是R1-Zero的自我进化能力,几乎和人类学习的逻辑一模一样。在MATH数据集测试中,1到3级的简单题,它在训练初期就彻底吃透了,准确率稳定在90%到95%之间;
4级的难题,准确率从一开始的78%,慢慢提升到95%;最难的5级题,更是从55%一路飙升到90%。这种循序渐进、慢慢攻克难题的节奏,和我们人类从易到难学习的过程,几乎没差。
当然也不能吹得太满,R1也有露怯的时候。遇到另类藏头诗、复数集合这类题目,它就容易翻车,连最基础的数数都可能出错,这些都是OpenAI等闭源模型没犯过的低级错误。
不过整体来看,优点远大于缺点,尤其是它的蒸馏技术,直接打破了行业常规认知。以前大家都觉得,推理能力是大模型的专属,小模型根本学不会,只能做些简单任务。
但R1偏要打破这个固有印象,通过蒸馏技术,把自己的推理能力成功传给了1.5B、7B、14B、70B等不同规模的小模型。
咱们可别忽略DeepSeek的小动作,最近它的官方应用刚加上语音输入功能,再加上之前除夕发布的多模态模型Janus-Pro,很明显是在悄悄布局多模态赛道。
Janus-Pro的7B版本,文生图的指令执行能力比DALL-E 3还强,而且能在浏览器本地运行,不用依赖云端算力,普通用户也能轻松使用。
更关键的是,这两个模型已经落地到医疗场景,在深圳的医院里辅助医生阅片,肿瘤检测精度能达到0.08毫米,把原本42分钟的会诊时间压缩到14分钟,大大提升了诊疗效率。
这野心可不小,摆明了要在开源多模态领域抢占先机。
结语
DeepSeek这波哪里是更论文,分明是给开源阵营扛大旗、树榜样。把训练细节、成本明细、失败经验全公开,不是傻,是硬实力给的底气和自信。它打破了闭源厂商的垄断壁垒,让技术回归普惠本质,逼着整个行业从比保密、比垄断,转向比透明、比真本事。春节前动作不断,从新架构到论文爆更,后续R2大概率有大动作。开源从来不是闭源的陪跑者,而是靠技术平权改写行业规则,这才是AI该有的样子,也是技术发展的真正方向。
股票投资公司提示:文章来自网络,不代表本站观点。